
Month: December 2011
[Quickstart] Using Neo4j and Tinkerpop to work with RDF. Part 2!
Another day, another reserve of patience to deal with trying to make this configuration work.
This is part 2 in my series of blog posts about how to get Neo4j with Tinkerpop running as an RDF triple store, assuming that you start not knowing/using Java.
When we left last-time, we had just downloaded the project source-code from a recent blog post by Davy Suvee (see my last post for the link). We opened it in Eclipse, and noticed that there are, like, 2000 broken dependency errors.
After a couple of hours of face-palming, I finally figured out what was going wrong and fixed it. Which brings us to…
STEP 7: Understand how Eclipse and Maven work together.
So you know in Ruby, you type ` gem install unicorn_magic `, some stuff downloads, and from then on your Ruby scripts just have to include ` require unicorn_magic `, and everything just works? Well, when you install a gem in Ruby, it downloads it into some magic folder (I’m not exactly sure where, but unless you care about which version of a gem you’re using, it doesn’t really matter since the programmer is well abstracted from the guts of the language), and from then on, the Ruby interpreter is smart enough to see ` require unicorn_magic ` and think “I should go look in my special magical jewel box for unicorn_magic, and then automatically make it available to my programmer friend so that he can live in the land of smiles and rainbows."
Java doesn’t do that. Java does not care about rainbows and smiles.
Instead, Java has "the classpath”. I’m probably butchering this concept, but as far as I understand it, individual Java projects have to explicitly tell the compiler where to go look for any external packages of code they want to include. They do that by specifying a classpath, which is a set of file-paths that Java will scan through to see if it can find the packages you specified.
So if you want to include packages (like, for example, the entire Tinkerpop framework), you have two options:
1) You download individual .jar files (i.e. “java archive” files, which contain compressed bundles of classes, which, remember, all Java code has to be contained within. For some reason.), and then you tell your project where to find those jars. To do that in Eclipse, you right click on your project, click Build Path –> Configure Build Path –> Add External Jars, then add packages one by one.
Fortunately, we won’t have to do that, because we can:
2) Use Maven. So Maven does a lot of stuff, but for our purpose here, it’s most important function is automatically managing dependencies.
The basic way that Maven works is by inserting a “pom.xml” (i.e. “Project Object Model”, since everything in Java is an object!) into your project. This xml file specifies the exact configuration of your project, most crucially all of the dependencies.
So if we take a look at the neo4j-sail-test project we have open in eclipse from the last post, and double click on pom.xml, eclipse will pop open a set of windows that walk you through the file. Let’s skip those and look directly at the xml, by clicking the “pom.xml” box on the bottom edge of the main sub-window.

Here you’ll see a bunch of <dependency> blocks that specify all the external packages this project is dependent on.
When you’re out on the internets, especially on github trying to pick up an open source tool to use, you’ll often see blocks that look like this:
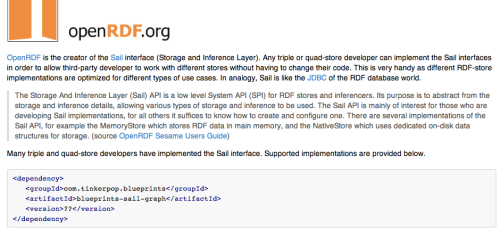
That chunk of XML is a Maven dependency. So if you wanted to use this Sail Ouplemntation pictured above, you would just need to add this xml chunk into your pom.xml file, inside of the <dependencies></dependencies> tags.
Of course, it’s not quite that easy. You still have to tell Maven to actually go get those files so that your project can use them.
To do that, you command-line into your project’s main folder and type:
% mvn clean install
If you have Maven installed correctly (see details in the last post if not), you should see a big rush of text, which will end with something looking like this:

What Maven is (basically) actually doing here is reading through your XML, looking at all the packages you said you needed, finding them in a centralized online repository, and then copying them into a folder on your hard-drive.
By default, that folder is located at
~/.m2
(The “.” in front of a name in OSX means the file/folder is hidden, and won’t be visible in the Finder by default. You can override the finder settings to show hidden folders (Google to see how), but it does lead to a lot of visual clutter. You can also just command-line your way into any hidden folder.)
Now for the somewhat tricky part…
Remember that we confirmed early that Eclipse has a plugin called M2Eclipse, i.e. Maven for Eclipse. That plugin is supposed to tell Eclipse to automatically add the .m2 repository to your classpath, so that projects can automatically find the packages they depend on there.
But for me, Eclipse was not looking inside that folder, which is why I was getting all those dependency errors. You need to make sure Eclipse knows where to look. Inside your Preferences menu, you should be able to find this window (Java–>Build Path–>Classpath Variables), which should have the line you see at the bottom here, “M2_Repo” etc…

If that line isn’t there, or if it is and you’re still getting dependency errors, you need to figure out how make this work correctly. For me, the solution was to go the command line and type:
% mvn eclipse:clean
then
% mvn eclipse:eclipse
That seems to have resolved it, though I’m not actually sure why. If this doesn’t work for you, let me know and I’ll see if I can help.
Okay…getting close! Just one more irritating tweak.
STEP 8: Fix the memory allocation
So Java has built in limits of how much memory running processes are allowed to use. If you’re doing anything large scale with the semantic web, you will often hit these limits. And this case is no exception – when I ran the neo4j-sail-test program in Eclipse, I got a “Java heap space” error.
Luckily, there is a fix. You need to explictly tell the program you’re using that it’s allowed to use more memory, by starting it with the argument
-Xmx[HOW_EVER_MUCH_MEMORY_YOU_WANT]m
e.g.
% java -jar -Xmx5000m unicorn_hunter.jar
With a program you run from the command line, that’s easy enough. For a program you build in Eclipse, it’s less obvious. What we need to do is edit the configuration file Eclipse uses when it starts, which is called “eclipse.ini”. Where is this file? Not in the Eclipse root directory!
Instead, it’s INSIDE THE APP

To get to it, go to the directory where you’ve installed Eclipse. For me, it’s /usr/local/eclipse.
From there, type:
% cd Eclipse.app/Contents/MacOS
Your eclipse.ini file is in here. Open it with a text editor, e.g.
% emacs eclipse.ini
and find the line that says something like -Xmx384m, and change it to the biggest number your system can handle. (For me, -Xmx5000m).
Save that file. Now…
STEP 9: RUN NEO4J-SAIL-TEST!
If you’ve followed these directions (and don’t have any other random, random problems), you should see:
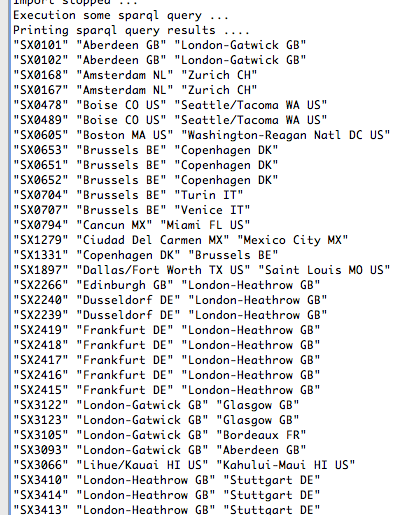
Congratulations! You’ve just used Neo4j and Tinkerpop to execute a SPARQL query!
My plan from here is to use the neo4j-sail-test project and tweak the code to do what I personally need.
Let’s see how that goes…
Hope you’ve enjoyed this intro, that it works for, and that it doesn’t obsolesce too quickly. If you run into any problems, leave a comment or shoot an email and I’ll see if I can help!
[Quickstart] Using Neo4j and Tinkerpop to work with RDF. Part 1!
[Warning: This is another super-technical post. If you don’t know what the Semantic Web and RDF are, this will be incomprehensible.]
In my last post, I talked about my attempt, as a novice programmer currently capable of only rudimentary Python and not much else, to use Neo4j as an RDF triple store so that I could work with the DBpedia dataset on my laptop. Tinkerpop is an open-source set of tools that lets you magically convert Neo4j into a fully functional triplestore.
My conclusion from that attempt was that using only Python to set up and control Neo4j for RDF is basically impossible.
To reiterate why I’m doing this in the first place: the DBPedia dataset is fascinating and I want to explore it. But the web interface has frustrating limitations (especially the fact that it will simply time out for non-trivial SPARQL queries, and also that I can’t easily download the input to feed into other programs.) So, I want to host the data locally so that I can let my laptop chug away for as long as I damn please answering my queries.
I’m still determined to accomplish that goal, so my new plan is to just bite the bullet and teach myself “just enough Java” (JeJ. Palindr-acronym!) to make this all work. I’ve hesitated to learn Java, since it is, well…extremely daunting.
As of six months ago, I knew basically nothing about programming. Since then, I’ve taught myself rudimentary Ruby (+ Rails) and rudimentary Python (+ Django), both of which are very nice, syntactically simple languages with excellent online “getting-started” resources. For Ruby, I recommend The Little Book of Ruby, or if you’re in for a more psychedelic experience, The Poignant Guide to Ruby. For Rails, I used Michael Hartl’s online Ruby Tutorial (there’s a link to a free HTML version buried on that page somewhere.) For Python, you can’t go wrong with Learn Python the Hard Way. MIT’s Open Courseware Site also has an entire intro to CS class in Python. For Django, I’m working my way through the Django Book. Both languages also have strong, enthusiastic communities in New York which you can easily connect with in person through www.meetup.com. If I get a chance, I’ll write another post sharing all the cool resources I’ve found from trying to learn Ruby and Python.
Now for Java, on all of those points…not so much.
From my perspective as an outsider and a novice, the Java ecosystem looks huge, fragmented, confusing, and uninviting.
Now I will freely concede that I don’t know shit about Java (that’s why I’m trying to learn!), so many of things I say in this post may be deeply ignorant and wrong. If so, please point out any errors/idiocy to me and I’ll happily correct myself.
In this post, I’m going to try to walk you through the whole process of going
FROM: Knowing nothing but a simple scripting language like Python
TO: Knowing enough Java to set up and run a publicly accesible Neo4j server that uses Tinkerpop to process and serve RDF data.
I’m going to try to stick as few steps as possible so that you can follow along even if you’re a true beginner like me. I am going to have to presume that you know enough about the Semantic Web to know what RDF and SPARQL are and why you’d want to use them. If you don’t, that’s just too big a subject to tackle here, though I will try to eventually write an introductory blog post about those too. In the meantime, you can start with wikipedia for a brief overview of RDF and SPARQL, or learn the hard way by reading the W3C specifications for RDF and SPARQL.
So:
STEP 1: Make sure you have Java.
This post presumes that you’re using a Mac. Speaking as a long-time Mac-avoider who just recently ditched his Windows laptop for a new Macbook – if you’re using Windows and want to develop modern software, you need to get a Mac. Just do it.
(Protip: buy used. I got a five-day old Macbook Pro for $2k on Craigslist. It actually had a faulty battery, so the Apple Store gave me a brand new one, no questions asked. Ebay also has substantial markdowns. And if AppleCare is not included, SquareTrade warranties are apparently 90% as good for 50% of the cost.)
So, the basic way that Java works is:
1) You write some code, and save it in a .java file.
2) You compile your source code into .class files, which I presume are in byte-code.
3) A magical machine called “the Java Virtual Machine” magically translates your bytecode into binary which can be executed on whatever system you’re using. The JVM is what makes Java portable to so many different systems…you only have to write code that’s compatible with the JVM, which is the same on every system. Making the JVM compatible with the chipset in your refrigerator is someone else’s job.
So, from what I can tell, “having Java” on your computer means two different things:
1) You have “the Java Runtime Environment”, or “JRE”, which contains the JVM and lets your computer execute precompiled Java code.
2) You have “the Java Development Kit”, or JDK, which contains all the machinery to compile your raw Java source code into bytecode.
Some blogs are claiming that Apple has stopped shipping a JDK since Lion, though you probably have a JRE. I can’t honestly remember what was installed on my laptop when I got it, but to figure out what you have vs. need, just open a console and type:
% java -version
If you don’t have a JDK, you will apparently get explicit instructions on how to get one from Apple. (Oracle apparently just doesn’t feel like supporting Mac). You can also download the latest JDK and updates from the Apple Developer download site. I can’t find a static link but it should hopefully be obvious what to click. This stackoverflow post also has instructions. The latest version seems to be JDK6, though there seems to possibly be a version 7 on the near horizon.
STEP 2: Get Eclipse
Unlike Python, which is happy to run your hello_world.py script by itself in some random folder, Java has fairly rigid requirements for how the filesystem of your project has to be laid out. So while you probably could do everything in emacs, you can save yourself a lot of pain by using an IDE.
One of the most widely-used open source IDE is called Eclipse. In addition to being free, it has a plugin system that makes it (reasonably) easy to add in new functionality. Neo4j will ask us to install some plugins, so I recommend that you just use Eclipse for you development, unless you have a strong reason not to. You can download it here. Just unzip it and put the decompressed folder in whatever folder you want to keep your Java stuff in (for me it’s /Users/rogueleaderr/Programming/Java).
For some reason the drag-the-app-icon-into-your-applications-folder-to-install-on-Lion didn’t work for me (the app wouldn’t launch), but I was able to just put an alias to the app icon into the applications folder and thus add Eclipse to the launch dock.
STEP 3: Get Maven
Don’t you love how simple adding new packages in Ruby is? Isn’t “gem install cthulu-mod” easy and intuitive? Well, forget about that.
You’re going to be using Maven now. I’m still figuring out exactly what Maven does, but my understanding is that it’s a package manager on steroids. If you have Maven installed, you put an xml file “pom.xml” inside each Java project you do, and it specifies the complete structure and all dependencies of your project. So if you download someone else’s project, you can use Maven to automatically make sure that you have everything you’re going to need to run that project. I recommend scanning the wiki page for a quick overview of what Maven does.
To me, typing in “gem install XYZ” three times sounds easier, but hey…
You can download Maven from the Apache website here. Follow the directions on that page to install on Mac. Basically, decompress the file then put it where Apache tells you to, then add it to your shell path. (To add to your shell path, open your .bashrc or .zshrc file, which is a hidden file located inside your home directory “ ~/ ”. If this file doesn’t exist, just create it by typing “ % emacs .zshrc ” (or whatever your preferred text editor is). Then paste in the lines from the Apache install directions. Make sure you enter the right file locations, as I learned the hard way.)
STEP 4: Get Neo4j
As you hopefully know if you’ve read this far, Neo4j is a graph database. While I’ve been told that a graph database is theoretically formally equivalent to a relational database and can be used for almost all of the same things, graph databases are naturally particularly good at representing graph structures. RDF data naturally forms a graph structure, meaning that Neo4j is naturally pretty well suited for hosting RDF.
Neo4j is not as naturally well suited for RDF as a dedicated triplestore like Sesame or OWLIM. But it has one key advantage, which is why I’m testing it out in the first place:
The free open source version is apparently capable of working with billions of triples. Sesame works fine with up to ~100m triples, but even the pared down DBPedia dataset I’m trying to work with has around 1.5bln. My first attempt to “damn the torpedoes” and load everything into Sesame lead to some bizarre behavior. There are commerical solutions like OpenLink Virtuoso and Ontotext OWLIM which claim to work with 10bln+ triples, but those are rather expensive.
Hence, Neo4j gets my attention for now.
Neo4j comes in two forms:
1) A standalone server which you can get by clicking the download button on the Neo4j homepage. The upside of the standalone sever is that you can control it through REST. So if you want to stick with Python, this is probably the way to go. Neo4j does have some embedded Python bindings, but they’re fairly limited. The downside of the standalone sever is that, as far as I know, there is no way to use additional plugins like Tinkerpop, so you’re limited to what Neo4j can do out of the box.
2) A set of Java libraries. This is what we’re going to need, so that we get the full range of control and so that we can use Tinkerpop. Neo4j has a fairly extensive manual which explains how to get these libraries (the specific page is here.) Follow the directions there (including potentially installing an Eclipse plugin called M2Eclipse to let you use Maven directly inside of Eclipse. On my Eclipse install, M2E was already installed, but I’m not sure how to check the full plugin list (Eclipse is pretty freakin’ complicated). But if you open Eclipse–>Preferences and see a line for “Maven”, you’re probably good.
STEP 5: Learn Java
And this is where the paved roads end. From here on out, we’re going to be tying everything together directly in Java, and fighting bugs and dinosaurs as they attack.
User-friendly resources for learning Java seem to be rather scarce (please let me know if you find any.) My solution pro tems is to just go directly to the Oracle Java Tutorial and work through it. Obviously this leaves you about 3652 days short of the ten years you’re going to need to be any good at Java. But assuming you already know the basics of some object oriented programming language, it will give you just barely enough to muddle your way through getting this basic setup working. And crucially, it will teach you how the Java package system works, which is not particularly intuitive but will be crucial if we want to use Tinkerpop.
STEP 6: Get Tinkerpop
Well, I hope you enjoyed learning Java. That must have taken a while. You did go learn Java, right?
Well, just in case you didn’t – I’ll walk you through how to create a Neo4j interface using Tinkerpop. Most of this is ripped directly off of a recent blog post by Davy Suvee, found here. Davy provides some very helpful code, but he assumes a high level of Java fluency. I, on the other hand, will assume that you know no more than I do (i.e. nothing.)
So, start by reading Davy’s post. If you can follow and implement that, you don’t need me!
If not, then let’s start by downloading Davy’s code. Head over to the Github repository. If you don’t know how to use Github, Google yourself a tutorial…it’s pretty easy.
Now, within Eclipse, go to File –> Import. A dialog will pop up. Click Git –> Project From Git

Now click Next. Then copy in the URL of Davy’s project – https://github.com/datablend/neo4j-sail-test.git – last I checked. Now click “
clone.”

Make sure url is autopopulated in the next window, and click next again. You shouldn’t need to enter any github credentials to do this, but if you get an error, try entering yours (definitely worth signing up for a free account if you don’t have one.)

Just click next on the next screen:

And on the last screen, make sure you’re creating the repo where you want it. Then click finish. The repo should download. Eclipse will bring up the original import screen again, but just close it.

Now you have the files! But what to do with them?
For some reason, Eclipse does not let you open projects. ಠ_ಠ
So what you have to do is:
1. Create a new Java project. Make sure your Eclipse workspace is set to the same folder where you cloned the project off of Github (go to File – > Switch Workspace if it’s not). Give the new project the same name as the github repo you cloned. Click okay, and Eclipse should automatically open the neo4j-sail-test project.
2. Now you should have a project open in Eclipse, and you can get started trying to fix all the dependency errors and make this code run.
3. To do that, we’re going to have to get the actual Tinkerpop libraries, and add them to our “classpath”, which is what Java uses to figure out where to look for the files you tell it to import.
That’s hard. And I will try to figure that out tomorrow…stay tuned for part 2.
Using Neo4j Graph Database and Python to Work with RDF
Hello hypothetical reader!
As you may know, I’ve recently gotten very interested in something called “the Semantic Web.” If you don’t know what that, is stop reading now because this post will be incomprehensible.
If you do know what the Semantic Web is and have tried to work with it at all, you know that it can be a bit less than user friendly. I’ve spent the last couple of weeks testing various tools (you can find a probably-complete list of all the available semantic web tools here, and have found most of them to
1) Be very hard to learn
2) Require that you interact with them through Java.
As a programming n00b who can barely scrape together some Python, the ubiquitous Java requirement is frustrating. So I thought I would document my latest attempt to make a Java-based tool work with Python, in case anyone else finds him or herself trying to do the same thing, and would like to avoid having to figure everything out from scratch.
So…
What I am doing: Trying to use Neo4j as a triple store to host the “DBpedia ontology-based mapping” on my laptop, and interact with and query it exclusively through Python.
Why I am doing this: The DBPedia dataset is fascinating and I want to explore it. But the web interface has frustrating limitations (especially the fact that it will simply time out for non-trivial SPARQL queries, and also that I can’t easily download the input to feed into other programs.) So, I want to host the data locally so that I can let my laptop chug away for as long as I damn please answering my queries.
The result: After a couple of days of trying to make this work, my tentative conclusion is that doing this in exclusively in Python is functionally impossible. Something like 80% of the basic low-level tools (e.g. triple-stores, query processors) I’ve encountered in this space are written in Java and intended to be custom-adapted by Java developers. And something like 80% of the tools that are usable through Python or Ruby are just shims for the Java tools (i.e. hacked-together-plug-the-AC-plug-into-the-DC-outlet adapters). In some cases, it is possible to loosely control the Java tools with Python, but:
1) In most cases, only a small subset of the functionality is accesible through Python
2) The shims are mostly poorly maintained and documented, and if you’re like me, you’ll spend nearly as much time trying to make them work as it would take you to just learn rudimentary Java. And if you stick with the shims, you’ll end up with a much more fragile system.
3) Shims are flat-out not available for some key components in the stack like Tinkerpop, which looks like the only viable way to use Neo4j with RDF without having to custom-write data-upload and querying functionality in Python.
The upshot is that many of these tools do have some form of REST interface (i.e. if you get the Java component running by itself, you can use Python to control it by sending it messages through http).
So my new plan is to:
1) Build a web interface in Django
2) Learn just enough Java (JeJ) to build a server to run the backend.
3) Figure out some way to put the Java server online
4) Control the sever through REST using Python, and do all the input/output on the Django webpage.
In my next post, I’ll walk you step by by step through my experience learning just-enough-Java to get started using Neo4j as a triple store to back a Django-powered website.